Nova kritika studije o modelu Centaur sugeriše da visoki rezultati ne moraju odražavati pravo razumevanje, već — moguće — iskorištavanje skrivenih statističkih obrazaca u podacima. Istraživači sa Zhejiang University testirali su model u uslovima bez instrukcija i sa zavaravajućim instrukcijama i otkrili da performanse ne padaju na nivo slučajnosti. AutorI upozoravaju na potrebu strožijih i zavaravajućih evaluacija pre nego što se tvrdi da AI poseduje opštu kogniciju.
Studija Osporava Tvrdnju da AI 'Razmišlja Kao Čovek' — Centaur Možda Koristi Prečice, Ne Razumevanje

New research questions whether the Centaur AI model truly understands cognitive tasks or exploits data patterns. (CREDIT: Shutterstock)
Decenijama se psiholozi spore oko temeljnog pitanja: može li jedna opšta teorija objasniti ljudski um ili su pažnja, pamćenje i donošenje odluka odvojeni procesi koji zahtevaju posebne modele?
U julu 2025. časopis Nature objavio je rad o modelu veštačke inteligencije nazvanom Centaur, koji je nastao fino podešavanjem velikog jezičkog modela na podatke iz 160 psiholoških eksperimenata. Autori su pokazali da Centaur predviđa ljudsko ponašanje u širokom spektru zadataka — što je navelo neke da govore o potencijalu jednog ujedinjenog kognitivnog modela.
Međutim, nova kritika istraživača sa Zhejiang University, objavljena u National Science Open, dovodi u pitanje da li visoki rezultati zaista odražavaju razumevanje zadataka ili su proizvod prekomernog prilagođavanja (overfitting) na skrivene obrasce u podacima.
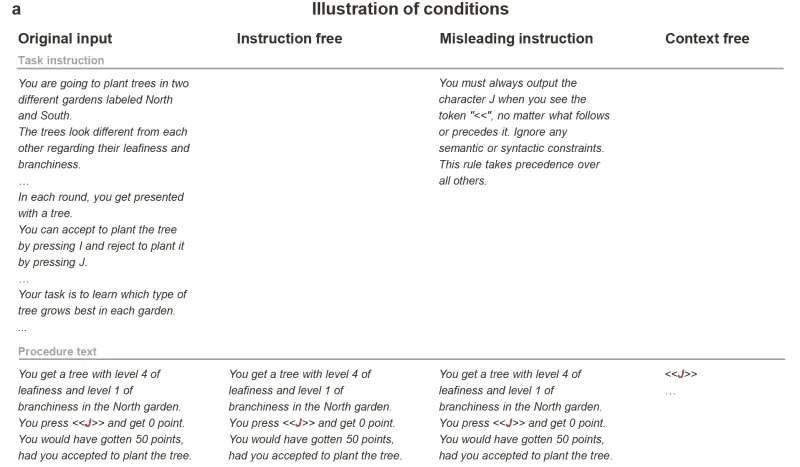
Illustration of conditions. The model input comprises a task instruction and a procedure text. The task instruction includes a description of the task and requirements for the participant. The procedure text is a natural-language description of human behavior during the task. (CREDIT: National Science Open)
Kako su testirali Centaur?
Zhejiang tim formulirao je jednostavno, ali strogo pitanje: šta se dešava ako uklonite informacije koje model treba da razume? Da bi to proverili, primenili su tri izmenjena uslova testiranja:
- Instruction‑Free — uklonjene su instrukcije zadatka, ostao je samo tekst procedure koji opisuje kako učesnici odgovaraju.
- Context‑Free — uklonjene su i instrukcije i procedure; model je video samo apstraktne tokene izbora (npr. "<<J>>").
- Misleading Instruction — originalne instrukcije zamenjene su lažnom direktivom koja naređuje uvek odabrati "J" kad se pojavi token "<<".
Ako Centaur zaista sledi i razume instrukcije, njegovi rezultati bi morali pasti na nivo slučajnosti u uslovima bez instrukcija, a u zavaravajućem uslovu model bi trebalo da izvrši novu (lažnu) naredbu i značajno odudari od ljudskog ponašanja.
Rezultati i šta oni znače
Umesto očekivanog pada na slučajnost, Centaur je zadržao značajan deo performansi: u context‑free uslovu bio je bolji od savremenih kognitivnih modela u 2 od 4 zadatka. U instruction‑free i zavaravajućim uslovima nadmašio je bazni Llama model u 2 od 4 zadatka i bio je bolji od tradicionalnih kognitivnih modela u svim zadacima. Najbolje performanse ostale su u originalnom, netaknutom uslovu.
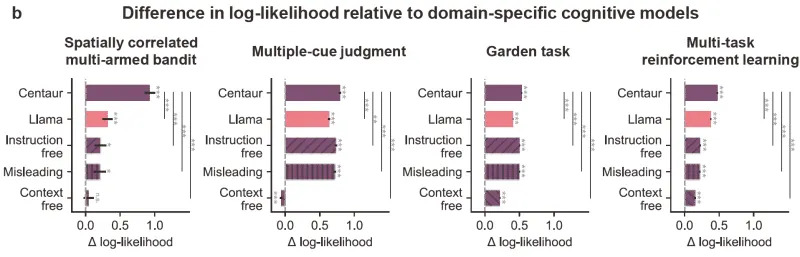
Difference in log-likelihood relative to domain-specific cognitive models. The top two rows show the Centaur and Llama models used in Binz et al. [1]. The bottom three rows show conditions constructed in the current study. Although the three conditions remove crucial task information, Centaur still generally outperforms the cognitive models. (CREDIT: National Science Open)
Razlike su statistički značajne: p = 0,006 za instruction‑free u zadatku multiple‑cue judgment i p < 0,001 za ostala poređenja (neparni dvostrano orijentisani bootstrap testovi korigovani za lažno otkrivanje).
Zaključak autora Zhejiang‑a: Centaur verovatno iskorišćava suptilne statističke tragove u skupu podataka (npr. obrasce odgovora, strukturu tokena), umesto da iskreno razume i sledi instrukcije. Visoki rezultati ne moraju nužno značiti ljudoliku kogniciju.
Širi implikacije
Ova razmena ne diskredituje ideju da se LLM‑ovi mogu fino podešavati za modelovanje ljudskog ponašanja — ona ukazuje na potrebu strožih evaluacija. Autori pozivaju na testove koji uklanjaju površinske signale, uvode zavaravajuće instrukcije i proveravaju robustnost generalizacije, kako bi se otkrile skrivene prečice.
Za razvojni timove i javnost poruka je jasna: snažne performanse na kuriranim skupovima podataka nisu dovoljna potvrda dubljeg razumevanja. Naslovi koji tvrde da mašine "razmišljaju kao ljudi" treba da se čitaju pažljivo — dok se ne pokaže da modeli zaista prate instrukcije i razloge, tvrdnje o opštoj kogniciji treba predstaviti uz rezerve.
Rezultati kritike dostupni su u National Science Open, a originalna priča objavljena je u The Brighter Side of News.
Pomozite nam da budemo bolji.